

Q1.User1、User2、User3 という名前の3人のユーザーがいます。
次の表に示す Fabric ワークスペースがあります。
User1 と User3 を含む Group1 という名前のセキュリティ グループがあります。
Fabric 管理者は、次の表に示すドメインを作成します。
User1 は Workspace3 という名前の新しいワークスペースを作成します。
Group1 を Domain1 の既定のドメインに追加します。
次の各ステートメントについて、ステートメントが正しい場合は [はい] を選択します。
それ以外の場合は [いいえ] を選択します。



回答
- (下記画像参照)
-

Domain1 の 既定のドメイン に Group1 を追加すると、Group1 メンバーが管理者である未割り当てワークスペースが Domain1 に割り当てられます。
Workspace3 は User1 が管理者で、User1 は Group1 のメンバーなので対象です。
ただし、ドメイン割り当ては ワークスペース ロールやアイテム権限には影響しません ため、User3 に Viewer は付与されません。
一方、Group1 のメンバーである User3 は Domain1 のドメイン共同作成者になります。
User2 は Group1 に含まれず、Workspace3 への Contributor も付与されません。
ドメイン – Microsoft Fabric | Microsoft Learn
Q2.KQL データベース内の Bike_Location という名前のテーブルにデータを読み込む Fabric イベントストリームがあります。
このテーブルには、次の列が含まれています: BikepointID、Street、Neighbourhood、No_Bikes、No_Empty_Docks、Timestamp。
データを利用できるように準備するため、変換ロジックとフィルター ロジックを適用する必要があります。
この解決策では、No_Bikes が 15 以上の場合に Sands End という名前の近隣地区のデータを返す必要があります。
結果は No_Bikes の昇順で並べ替える必要があります。
解決策: 次のコード セグメントを使用します: bike_location | filter Neighbourhood == “Sands End” and No_Bikes >= 15 | sort by No_Bikes | project BikepointID, Street, Neighbourhood, No_Bikes, No_Empty_Docks, Timestamp | project BikepointID, Street, Neighbourhood, No_Bikes, No_Empty_Docks, Timestamp。
この解決策は目標を満たしていますか。
A. はい
B. いいえ
回答
- B. いいえ
-
フィルター条件は Sands End かつ No_Bikes が 15 以上であり、project も必要な列を返すため問題ありません。
しかし KQL の sort 演算子では、asc または desc を省略すると既定は desc です。
そのため `sort by No_Bikes` は降順となります。
昇順にするには sort by No_Bikes asc と明示する必要があります。
このコードは 要件の昇順を満たしません。
sort 演算子 – Kusto | Microsoft Learn
Q3.Fabric ワークスペースが5つあります。
監視ハブを使用して項目の実行を監視しています。
特定の項目がどのワークスペースで実行されているかを特定する必要があります。
監視ハブでどの列を表示する必要がありますか。
A. 開始時刻
B. 容量
C. アクティビティ名
D. 送信者
E. 項目の種類
F. ジョブの種類
G. 場所
回答
- G. 場所
-
監視ハブのアクティビティ一覧では、実行された Fabric 項目の状態や開始時刻などを確認できます。
特定の項目がどのワークスペースで実行されたかを確認するには、場所 列を参照します。
Microsoft Learn でも、場所は 項目アクティビティを表示する元のワークスペース を表すフィルターとして説明されています。
開始時刻、容量、送信者などは実行元ワークスペースの識別には適しません。
試験では Location はワークスペースを示す列 と覚えることが重要です。
監視ハブ: Fabric アクティビティの表示と追跡 – Microsoft Fabric | Microsoft Learn
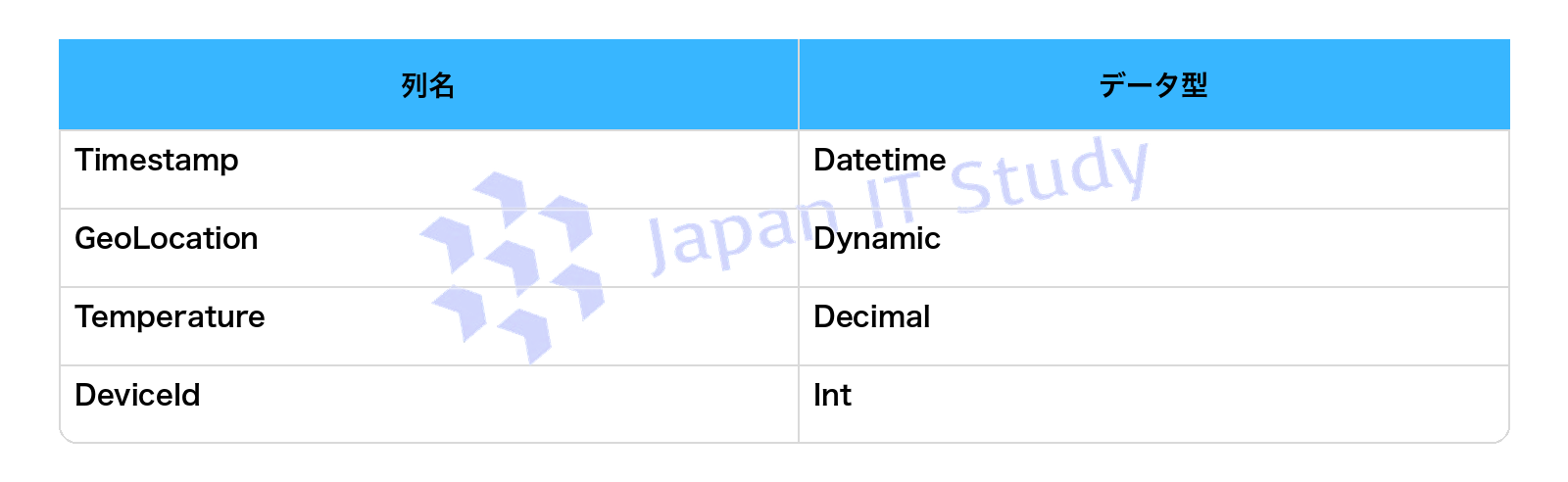
Q4.Stream と Reference という名前の2つのテーブルを含む KQL データベースがあります。
Stream には次の形式でストリーミング データが含まれています。
Reference には次の形式で参照データが含まれています。
どちらのテーブルにも数百万行が含まれています。
次の KQL クエリセットがあります: 01 Stream 02 | extend lat = todecimal(GeoLocation.Latitude), long = todecimal(GeoLocation.Longitude) 03 | join kind=inner Reference on DeviceId 04 | project Timestamp, lat, long, Temperature, DeviceName 05 | filter Temperature >= 10 06 | render scatterchart with (kind = map)。
KQL クエリセットの実行時間を短縮する必要があります。
解決策: 結合の種類を kind=outer に変更します。
この解決策は目標を満たしていますか。

A. はい
B. いいえ
回答
- B. いいえ
-
KQL の join 演算子で指定できる結合の種類には inner、leftouter、rightouter、fullouter などがありますが、kind=outer は有効な結合の種類ではありません。
また、外部結合は一致しない行も含めるため、通常は処理対象が増えます。
実行時間短縮には、結合前に filter を早く適用して処理行数を減らす、必要列だけを射影するなどが重要です。
この変更は 性能改善の要件を満たしません。
join 演算子 – Kusto | Microsoft Learn
Q5.Workspace1_DEV という名前の Fabric ワークスペースがあり、次の項目が含まれています: 10個のレポート、4つのノートブック、3つのレイクハウス、2つのデータ パイプライン、2つの Dataflow Gen1 データフロー、3つの Dataflow Gen2 データフロー、5つのセマンティック モデル(それぞれにスケジュール更新ポリシーがあります)。
Workspace1_DEV から Workspace1_TEST という名前の新しいワークスペースに項目を移動するために、Pipeline1 という名前のデプロイ パイプラインを作成します。
Workspace1_DEV から Workspace1_TEST にすべての項目をデプロイします。
次の各ステートメントについて、ステートメントが正しい場合は [はい] を選択します。
それ以外の場合は [いいえ] を選択します。

回答
- (下記画像参照)
-

Fabric のデプロイ パイプラインでは、対応する項目のメタデータや定義をステージ間でコピーしますが、セマンティック モデルなどの データはコピーされずメタデータのみ が対象です。
Dataflow Gen1 は現在 Power BI データフローとして扱われるレガシー系の項目ですが、デプロイ パイプラインの対象であるため Dataflow Gen1 はデプロイされます。
一方、セマンティック モデルの スケジュール更新はコピーされません。
したがって、順に「いいえ、はい、いいえ」です。
Microsoft Fabric デプロイ パイプライン プロセス – Microsoft Fabric | Microsoft Learn
Q6.会社には開発者チームがあります。
このチームは、データの変換に使用される再利用可能なコードの Python ライブラリを作成しています。
ノートブックを使用して抽出、変換、読み込み(ETL)ソリューションを開発するために使用される Workspace1 という名前の Fabric ワークスペースを作成します。
Workspace1 の新しいノートブックで、ライブラリが既定で使用できるようにする必要があります。
どの3つのアクションを順番に実行する必要がありますか。
回答するには、適切なアクションをアクションの一覧から回答領域に移動し、正しい順序に並べ替えてください。

回答
- (下記画像参照)
-

Fabric のノートブックで再利用ライブラリをワークスペース標準として使うには、まず 環境を作成 し、その環境に必要な Python ライブラリを追加します。
環境は Spark ランタイム、コンピューティング、ライブラリをまとめて管理するワークスペース項目です。
最後に 既定の環境として設定 すると、新しいノートブックがワークスペースの既定値としてそのライブラリ構成を継承します。
プール作成やランタイム変更だけでは、ライブラリを既定で利用可能にする要件を満たしません。
Fabric で環境を作成、構成、使用する – Microsoft Fabric | Microsoft Learn
Q7.Azure イベント ハブがあります。
各イベントには、次のフィールドが含まれています: BikepointID、Street、Neighbourhood、Latitude、Longitude、No_Bikes、No_Empty_Docks。
イベントを取り込む必要があります。
このソリューションでは、Neighbourhood の値が Chelsea であるイベントのみを保持し、保持されたイベントを Fabric レイクハウスに格納する必要があります。
何を使用する必要がありますか。
A. KQL クエリセット
B. イベントストリーム
C. ストリーミング データセット
D. Apache Spark Structured Streaming
回答
- B. イベントストリーム
-
Fabric のイベントストリームは、Azure Event Hubs などのリアルタイム ソースからイベントを取り込み、処理して宛先へルーティングできます。
要件では、Neighbourhood が Chelsea のイベントだけを残すため、イベントストリームの フィルター処理 を使用します。
その後、保持したイベントを レイクハウス宛先 に送信して保存できます。
KQL クエリセットは主に取得済みデータの照会用であり、ストリーミング データセットや Spark よりも、この要件には イベントストリームが最適 です。
リアルタイム イベントの取り込み、フィルター処理、変換を行い、Microsoft Fabric レイクハウスに送信する – Microsoft Fabric | Microsoft Learn
Q8.KQL データベース内の Bike_Location という名前のテーブルにデータを読み込む Fabric イベントストリームがあります。
このテーブルには、次の列が含まれています: BikepointID、Street、Neighbourhood、No_Bikes、No_Empty_Docks、Timestamp。
データを利用できるように準備するため、変換ロジックとフィルター ロジックを適用する必要があります。
この解決策では、No_Bikes が 15 以上の場合に Sands End という名前の近隣地区のデータを返す必要があります。
結果は No_Bikes の昇順で並べ替える必要があります。
解決策: 次のコード セグメントを使用します: SELECT BikepointID, Street, Neighbourhood, No_Bikes, No_Empty_Docks, Timestamp FROM bike_location WHERE neighbourhood = ‘Sands End’ AND no_bikes >= 15 ORDER BY no_bikes。
この解決策は目標を満たしていますか。
A. はい
B. いいえ
回答
- B. いいえ
-
提示された SELECT 文は条件と並べ替えの内容自体は要件に近いですが、KQL データベースのクエリ エディターで T-SQL を実行するには、空の T-SQL コメント行(–)で開始 する必要があります。
この指定がないコードは KQL として解釈 されるため、SQL 文として実行されません。
KQL クエリセットでは KQL が主要言語であり、この解決策は 目標を満たしません。
T-SQL – Kusto | Microsoft Learn
Q9.Fabric データ パイプラインを使用してデータ読み込みパターンを構築しています。
ソースは、25個のテーブルを含む Azure SQL データベースです。
宛先はレイクハウスです。
ウェアハウスで、展示に示されているように Control.Object という名前の制御テーブルを作成します([Exhibit] タブをクリックします)。
1回の実行で、制御テーブルに一覧表示されたテーブルの動的取り込みをサポートするデータ パイプラインを構築する必要があります。
どの3つのアクションを順番に実行する必要がありますか。

回答
- (下記画像参照)
-

制御テーブルにある複数テーブルを1回の実行で動的に取り込むには、まず Lookup アクティビティ で Control.Object を照会し、コピー対象のスキーマとテーブル一覧を取得します。
次に ForEach アクティビティ でその一覧を反復処理します。
各反復の中に Copy data アクティビティを配置すると、現在の項目を使ってソース表からレイクハウスの Delta テーブルへコピーできます。
Get metadata は既存オブジェクトのメタデータ取得用で、制御テーブルの行一覧取得には適しません。
ForEach アクティビティ – Microsoft Fabric | Microsoft Learn
Q10.Workspace1 という名前の Fabric ワークスペースがあり、Notebook1 という名前のノートブックが含まれています。
Workspace1 で、Notebook2 という名前の新しいノートブックを作成します。
Notebook2 を Notebook1 と同じ Apache Spark セッションにアタッチできるようにする必要があります。
何を行う必要がありますか。
A. ノートブックの高コンカレンシーを有効にします。
B. Spark プールの動的割り当てを有効にします。
C. ランタイム バージョンを変更します。
D. エグゼキューターの数を増やします。
回答
- A. ノートブックの高コンカレンシーを有効にします。
-
Fabric ノートブックで既存の Spark セッションに別のノートブックをアタッチするには、ワークスペースで ノートブックの高コンカレンシー を有効にします。
高コンカレンシー モードでは、互換性のあるノートブックが 同じ Spark セッションを共有 できます。
動的割り当て、ランタイム変更、エグゼキューター数の増加は Spark のリソースや実行環境に関する設定であり、Notebook2 を Notebook1 と同じセッションへ接続する要件には直接対応しません。
ノートブックの高コンカレンシー モードを構成する – Microsoft Fabric | Microsoft Learn
