

Q1.Unity Catalogが有効化され、Catalog1という名前のカタログを含むAzure Databricksワークスペースがあります。
Catalog1にはTransactionsという名前のテーブルがあります。
Transactionsには次の列が含まれています。
transaction_id(トランザクションID)
customer_name(顧客名)
email_address(メールアドレス)
credit_card_number(クレジットカード番号)
transaction_amount(取引金額)
ビジネスアナリストがTransactionsテーブルのすべての行を照会できるようにする必要があります。
ソリューションは、次の要件を満たす必要があります。
アナリストがemail_address列とcredit_card_number列の完全な値を参照できないようにする。
アナリストが各メールアドレスの「@」より後ろの値のみを参照できるようにする。
アナリストが各クレジットカード番号の末尾4桁のみを参照できるようにする。
アナリストがエラーなしでテーブルを照会できるようにする。
最小特権の原則に従う。
何を行う必要がありますか。
A. アナリストにTransactionsテーブルのSELECT権限を付与し、列レベルの暗号化を適用します。
B. 機密データを含まない列についてのみ、アナリストにSELECT権限を付与します。
C. アナリストにTransactionsテーブルのSELECT権限を付与し、行レベルフィルターを実装します。
D. アナリストにTransactionsテーブルのSELECT権限を付与し、email_address列とcredit_card_number列に列マスクを適用します。
回答
- D. アナリストにTransactionsテーブルのSELECT権限を付与し、email_address列とcredit_card_number列に列マスクを適用します。
-
列マスクは、元の列値を利用者へ直接返さず、Unity Catalogに登録したユーザー定義関数の結果へ置き換える機能です。email_addressには「@」以降を返す関数、credit_card_numberには末尾4桁だけを返す関数を設定できます。
テーブルへのSELECT権限を付与するため、アナリストは全行と非機密列をエラーなく照会できます。
行フィルターは行自体を制限する機能であり、今回の列値の秘匿には適しません。
機密列のSELECT権限を外す方法も照会エラーの原因となるため、列マスクが最小特権の要件を満たします。
行フィルターと列マスク
列mask句
Q2.Unity Catalogが有効化され、catalog1という名前のカタログを含むAzure Databricksワークスペースがあります。
group1という名前のグループがあります。
catalog1にschema1という名前のスキーマを作成する予定です。
group1が次の要件を満たすようにする必要があります。
schema1にテーブルを作成できる。
テーブルを変更および照会できる。
スキーマとそのオブジェクトに対するアクセス許可を付与できない。
SQLステートメントをどのように完成させる必要がありますか。回答するには、回答領域で適切な選択肢を選択してください。

回答
- 下記画像参照
-
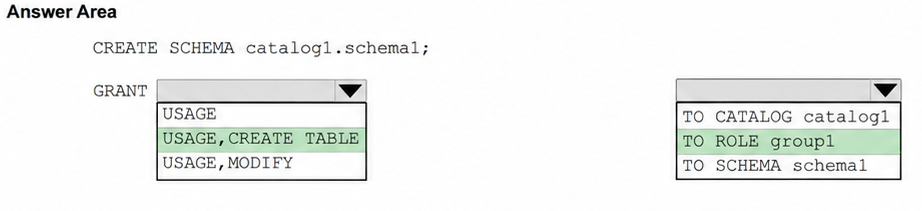
出題上は、USAGEによってschema1を使用でき、CREATE TABLEによってスキーマ内にテーブルを作成できます。MANAGEや所有権は付与していないため、group1にはアクセス許可を管理する権限を与えません。
なお、現在のUnity CatalogではUSAGEではなくUSE CATALOGとUSE SCHEMAを使用し、付与先もTO ROLEではなくTO principalの形式です。
また、既存の全テーブルを照会・変更させる場合はSELECTとMODIFYを別途付与します。
この問題は旧構文を前提とした出題です。
Unity カタログ権限リファレンス
GRANT
Q3.Unity Catalogが有効になっているAzure Databricksワークスペースがあります。
既存のスキーマにVolume1という名前の外部ボリュームを作成する必要があります。
Volume1は、Azure Storageコンテナー内のファイルを公開する必要があります。
ソリューションは、次の要件を満たす必要があります。
認証でDatabricks内に資格情報を保存する必要がないようにする。
ユーザーがファイルにアクセスできるが、ファイルを変更できないようにする。
最小特権の原則に従う。
どの種類の認証を構成し、どのアクセス許可をユーザーに付与する必要がありますか。
回答するには、回答領域で適切な選択肢を選択してください。

回答
- 下記画像参照
-

Azure Databricks Access ConnectorはマネージドIDを使用してAzure Storageへ接続するため、Databricks内にクライアントシークレットなどの資格情報を保存したり、ローテーションしたりする必要がありません。
READ VOLUMEはボリューム内のファイルとディレクトリの読み取りを許可しますが、追加、削除、変更は許可しません。BROWSEはオブジェクトを検出するための権限であり、ファイル内容を読み取れません。
WRITE VOLUMEはファイルの変更を許可するため要件外です。したがって、DatabricksアクセスコネクタとREAD VOLUMEの組み合わせが最小特権を満たします。
両名称は現在も使用されている正式名称です。
Azure Data Lake Storage Gen2 (ADLS Gen2) 外部の場所に接続する
Q4.注:このセクションには、同じシナリオと問題に基づく1つ以上の問題セットが含まれています。
各問題では、その問題に対する固有のソリューションが提示されます。
提示されたソリューションが記載された目標を満たすかどうかを判断する必要があります。
セット内の複数のソリューションが問題を解決する場合があります。
また、どのソリューションも問題を解決しない場合もあります。
このセクションの問題に回答すると、前の問題に戻ることはできません。
そのため、これらの問題はレビュー画面に表示されません。
レイクハウスを含み、Unity Catalogが有効になっているWorkspace1という名前のAzure Databricksワークスペースがあります。
DB1という名前のMicrosoft SQL Serverデータベースへの接続があります。
DB1のスキーマとテーブルを公開し、次の要件を満たす必要があります。
スキーマとテーブルをDatabricksで照会できること。
スキーマとテーブルが他のUnity Catalogオブジェクトと並んで表示されること。
データがDatabricks管理ストレージにコピーされないこと。
ソリューション:Lakeflow Connectパイプラインを作成し、DB1に接続します。
このソリューションは目標を満たしますか。
A. はい。
B. いいえ。
回答
- B. いいえ。
-
Lakeflow ConnectはSQL ServerのデータをAzure Databricksへ取り込み、宛先のDeltaテーブルに格納するため、「データをDatabricks管理ストレージへコピーしない」という要件を満たしません。
DB1のデータを移動せずに照会するには、Lakehouse Federationを使用して接続から外部カタログを作成します。
外部カタログは外部データベースのスキーマとテーブルをUnity Catalog内に表示し、元のSQL Server上のデータへ読み取り専用でアクセスできます。
したがって回答はBです。
Lakeflow ConnectとLakehouse Federationは現在も使用されている正式名称です。
Microsoft SQL Server でフェデレーション クエリを実行する
外部カタログの管理と操作
Q5.注:このセクションには、同じシナリオと問題に基づく1つ以上の問題セットが含まれています。
各問題では、その問題に対する固有のソリューションが提示されます。
提示されたソリューションが記載された目標を満たすかどうかを判断する必要があります。セット内の複数のソリューションが問題を解決する場合があります。
また、どのソリューションも問題を解決しない場合もあります。
このセクションの問題に回答すると、前の問題に戻ることはできません。
そのため、これらの問題はレビュー画面に表示されません。
レイクハウスを含み、Unity Catalogが有効になっているWorkspace1という名前のAzure Databricksワークスペースがあります。
DB1という名前のMicrosoft SQL Serverデータベースへの接続があります。
DB1のスキーマとテーブルを公開し、次の要件を満たす必要があります。
スキーマとテーブルをDatabricksで照会できること。
スキーマとテーブルが他のUnity Catalogオブジェクトと並んで表示されること。
データがDatabricks管理ストレージにコピーされないこと。
ソリューション:Databricksアクセスコネクタを作成します。
このソリューションは目標を満たしますか。
A. はい。
B. いいえ。
回答
- B. いいえ。
-
DB1のスキーマとテーブルをデータコピーなしでUnity Catalogに公開するには、既存の接続を使用して外部カタログを作成します。
外部カタログは外部データベースを反映し、Databricksから読み取り専用のフェデレーションクエリを実行できます。
Azure Databricksアクセスコネクタは、マネージドIDをDatabricksへ関連付けてAzure Storageなどへの認証に利用するリソースであり、SQL ServerのスキーマやテーブルをUnity Catalogへ登録する機能ではありません。
したがって、このソリューションは要件を満たしません。Lakehouse Federation、外部カタログ、およびAzure Databricksアクセスコネクタはいずれも現在使用されている正式名称です。
Microsoft SQL Server でフェデレーション クエリを実行する
外部カタログの管理と操作
Q6.注:このセクションには、同じシナリオと問題に基づく1つ以上の問題セットが含まれています。
各問題では、その問題に対する固有のソリューションが提示されます。
提示されたソリューションが記載された目標を満たすかどうかを判断する必要があります。
セット内の複数のソリューションが問題を解決する場合があります。
また、どのソリューションも問題を解決しない場合もあります。
このセクションの問題に回答すると、前の問題に戻ることはできません。
そのため、これらの問題はレビュー画面に表示されません。
レイクハウスを含み、Unity Catalogが有効になっているWorkspace1という名前のAzure Databricksワークスペースがあります。
DB1という名前のMicrosoft SQL Serverデータベースへの接続があります。
DB1のスキーマとテーブルを公開し、次の要件を満たす必要があります。
スキーマとテーブルをDatabricksで照会できること。
スキーマとテーブルが他のUnity Catalogオブジェクトと並んで表示されること。
データがDatabricks管理ストレージにコピーされないこと。
ソリューション:カタログ エクスプローラーで外部カタログを作成します。
このソリューションは目標を満たしますか。
A. はい。
B. いいえ。
回答
- A. はい。
-
外部カタログは、外部データベースをUnity Catalog内に反映し、スキーマとテーブルを他のカタログオブジェクトと同様に表示して照会できるようにします。
Lakehouse Federationによるクエリフェデレーションでは、SQL Server上のデータをその場所に保持したまま読み取り専用で照会するため、Databricks管理ストレージへのコピーは発生しません。
したがって、カタログ エクスプローラーで外部カタログを作成するソリューションは、すべての要件を満たします。
「外部カタログ」「Lakehouse Federation」「カタログ エクスプローラー」は現在も使用されている正式名称です。
クエリフェデレーションとは
外部カタログの管理と操作
Q7.注:このセクションには、同じシナリオと問題に基づく1つ以上の問題セットが含まれています。
各問題では、その問題に対する固有のソリューションが提示されます。
提示されたソリューションが記載された目標を満たすかどうかを判断する必要があります。
セット内の複数のソリューションが問題を解決する場合があります。
また、どのソリューションも問題を解決しない場合もあります。
このセクションの問題に回答すると、前の問題に戻ることはできません。そのため、これらの問題はレビュー画面に表示されません。
レイクハウスを含み、Unity Catalogが有効になっているWorkspace1という名前のAzure Databricksワークスペースがあります。
DB1という名前のMicrosoft SQL Serverデータベースへの接続があります。
DB1のスキーマとテーブルを公開し、次の要件を満たす必要があります。
スキーマとテーブルをDatabricksで照会できること。
スキーマとテーブルが他のUnity Catalogオブジェクトと並んで表示されること。
データがDatabricks管理ストレージにコピーされないこと。
ソリューション:Unity Catalogに新しいネイティブカタログを作成します。
このソリューションは目標を満たしますか。
A. はい。
B. いいえ。
回答
- B. いいえ。
-
通常のネイティブカタログを新規作成しても、SQL Server上のDB1のスキーマやテーブルは自動的に反映されません。
データをコピーせずにUnity Catalog内へ表示して照会するには、既存の接続を使用し、Lakehouse Federationの外部カタログを作成する必要があります。
外部カタログは外部データベースをミラー化し、元のSQL Serverにデータを保持したまま読み取り専用クエリを実行できます。
したがって、このソリューションは要件を満たしません。
現行の公式ドキュメントでは、外部データベースを反映するオブジェクトを「外部カタログ」と呼びます。
クエリフェデレーションとは
外部カタログの管理と操作
Q8.サーバーレスコンピューティングを使用するAzure Databricksワークスペースがあります。
Lakeflow Jobsを使用してデータを取り込む必要があります。
新しいレコードは、利用可能になり次第処理する必要があります。
取り込みには、どの種類のジョブトリガーを使用する必要がありますか。
A. 手動
B. ファイル到着
C. スケジュール
D. 継続
回答
- D. 継続
-
継続トリガーはジョブを常時実行状態に保ち、実行が完了または失敗すると次の実行を開始します。
そのため、一定のスケジュールを待たず、新しいレコードを継続的に処理する要件に適しています。
ファイル到着トリガーは、監視対象のUnity Catalogストレージ場所に新しいファイルが到着した場合に限定されます。
本問では入力がファイルとは指定されていないため、継続トリガーが適切です。
なお、Lakeflow Jobsの継続トリガーは、SparkのContinuous Processingトリガーとは別の機能です。
Lakeflow Jobsは現在の正式名称です。
スケジュールとトリガーを使用してジョブを自動化する
構造化ストリーミングの運用に関する考慮事項
Q9.Unity Catalogが有効化され、Salesという名前のマネージドDeltaテーブルを含むAzure Databricksワークスペースがあります。
Salesにはトランザクションデータが格納されており、次の列が含まれています。
transaction_id(文字列)
transaction_date(日付)
amount(10進数)
テーブルレベルのデータ品質強制を使用して、次のデータ品質要件を実装する必要があります。
amountは0より大きくなければならない。
transaction_idをNULLにしてはならない。
無効なレコードは、Salesテーブルへのデータ書き込み時に拒否されなければならない。
何を行う必要がありますか。
A. SELECTステートメントでWHERE条件を使用し、クエリを実行する前にデータを検証します。
B. transaction_idがNULL、またはamountが0以下の行を除外するビューを作成します。
C. transaction_idにNOT NULL制約を追加し、amountにCHECK制約を追加します。
D. transaction_idがNULL、またはamountが0以下の場合に適用される行レベルセキュリティ(RLS)を構成します。
回答
- C. transaction_idにNOT NULL制約を追加し、amountにCHECK制約を追加します。
-
NOT NULL制約はtransaction_idへのNULLの格納を禁止し、CHECK制約でamount > 0を定義すると、条件を満たさない書き込みがテーブルレベルで拒否されます。
これらはDeltaテーブルで強制されるデータ品質制約です。
WHERE句やビューは照会時に無効な行を除外するだけで、元テーブルへの不正データの書き込みを防止できません。
RLSも行の参照範囲を制御する機能であり、データ品質検証には使用しません。
Unity Catalog、Deltaテーブル、NOT NULL制約、CHECK制約はいずれも現在使用されている正式名称です。
Azure Databricks の制約
ADD CONSTRAINT 句
Q10.Unity Catalogが有効化され、同じデータ型を使用するTable1およびTable2という名前の2つのDeltaテーブルを含むAzure Databricksワークスペースがあります。
Table1にはColumn1という名前の列があります。Table2にはColumn2という名前の列があります。
次のクエリを実行します。
SELECT Column1
FROM Table1
GROUP BY Column1
HAVING COUNT() > 1
INTERSECT
SELECT Column2
FROM Table2
GROUP BY Column2
HAVING COUNT() > 1;
クエリを実行すると、どのような結果になりますか。
A. 両方のテーブルに複数回出現する値が表示されます。
B. いずれか一方のテーブルに複数回出現する値が表示されます。
C. Table2には出現するが、Table1には出現しない値が表示されます。
D. Table1に複数回出現する値が表示されます。
回答
- A. 両方のテーブルに複数回出現する値が表示されます。
-
各SELECTでは、GROUP BYで列の値ごとに行をまとめ、HAVING COUNT(*) > 1によって、そのテーブル内に複数回出現する値だけを抽出します。
HAVINGはGROUP BYによる集計結果を条件で絞り込む句です。
INTERSECTは、前後のSELECT結果の両方に存在する値だけを返します。
ALLを指定していないため既定のDISTINCTとして処理され、結果内の重複も除去されます。
したがって、Table1とTable2の両方で複数回出現する値が1回ずつ表示されます。
INTERSECTやDeltaテーブルは現在も使用されている正式名称です。
集合演算子
HAVING 句
