

Q1.Azure Data Factory があり、Git リポジトリにはコラボレーション ブランチ main と、機能ブランチ abc および xyz が含まれています。
xyz ブランチで作成したパイプラインの変更をライブ サービスに公開する必要があります。
最初に何を行う必要がありますか。
A. データ ファクトリを公開する
B. プル リクエストを作成して変更を main ブランチにマージする
C. コードをリモート オリジンにプッシュする
D. プル リクエストを作成して変更を abc ブランチにマージする
回答
- B. プル リクエストを作成して変更を main ブランチにマージする
-
Azure Data Factory の Git 連携では、ライブ環境へ公開する前にコラボレーション ブランチへ変更を統合する必要がある。
機能ブランチ xyz の変更は直接公開できず、まず main ブランチへプル リクエストでマージ することでチーム共有状態となる。
その後に Publish 操作を実行するとライブ環境へ反映される。
したがって最初に行うべき操作は main へのマージであり、ブランチ戦略と公開フローの理解が重要である。
Azure Data Factory でのソース管理
Q2.Azure Data Factory インスタンス ADF1 と、Azure Synapse Analytics ワークスペース WS1 および WS2 があります。
ADF1 のパイプライン P1 と P2 において、コピー アクティビティの設定を最適化する必要があります。
WS1 から Data Lake へコピーする P1 と、Data Lake から WS2 の専用 SQL プールへコピーする P2 について、パフォーマンスを最大化するために適切な設定を選択してください。

回答
- (下記画像参照)
-

WS1 からのコピーでは PolyBase を使用することで大規模データの並列ロードが可能 となり、最も高いパフォーマンスを実現できます。
一方で、P2 はテキスト形式のファイルを扱うため PolyBase は利用できず Bulk insert を使用する必要があります。
この違いを理解することが重要であり、データ形式とロード方式の適合性が試験の重要ポイントです。
適切なコピー方式を選択することで Synapse の性能を最大化できます。
Azure Synapse Analytics とは
Q3.Azure IoT ハブからのデータを処理し、複雑な変換を実行する C# アプリケーションがあります。
アプリケーションをリアルタイム ソリューションに置き換える必要があります。
既存のコードをできるだけ再利用するには、どのサービスを選択する必要がありますか。
A. Azure Databricks
B. Azure Event Grid
C. Azure Stream Analytics
D. Azure Data Factory
回答
- C. Azure Stream Analytics
-
リアルタイム処理と既存 C# コードの再利用が要件であるため、Azure Stream Analytics が最適です。
特に IoT Edge 上で実行する場合、C# のユーザー定義関数(UDF)を利用して既存ロジックを再利用できる点が重要です。
Databricks は主にバッチ・Spark 処理、Event Grid はイベント通知、Data Factory はバッチ統合向けであり要件に適合しません。
したがって、リアルタイム分析と C# 再利用の両立が可能な Stream Analytics が正解です。
IoT Edge での Azure Stream Analytics
Q4.Azure Blob ストレージ アカウントにフォルダーがあり、120,000 個のファイルが含まれています。
毎日 1,500 個の新しいファイルが追加されます。
これらのデータを Azure Synapse Analytics に段階的に読み込み、処理時間を最小化する必要があります。
ファイルとフォーマットの最適な設定を選択してください。

回答
- (下記画像参照)
-

大量ファイルを効率的に処理するには、フォルダーでの時間ベースのパーティション分割(Timeslice partitioning)が重要です。
これにより新規データのみを対象に読み込みでき、スキャン量を削減できます。
また形式は列指向で圧縮効率の高い Apache Parquetを使用することで、I/O とクエリ性能が向上します。
CSV や JSON は行指向のため非効率です。
したがって、時間パーティション+Parquet形式の組み合わせが最適解となります。
外部テーブルの作成と使用
Q5.Azure Synapse Analytics のサーバーレス SQL プールで、Azure Data Lake Storage Gen2 内の Parquet ファイルから住所情報のみを取得するテーブルを作成する必要があります。
適切な Transact-SQL を選択してください。

回答
- (下記画像参照)
-
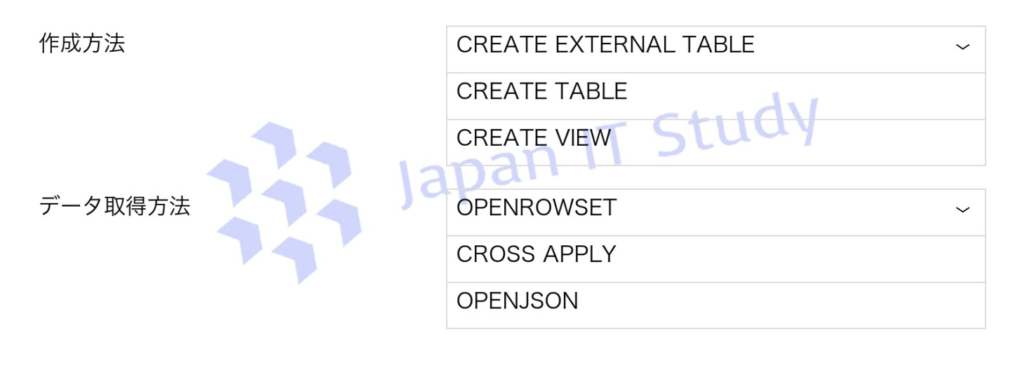
サーバーレス SQL プールでは外部データ参照に CREATE EXTERNAL TABLE を使用して外部ストレージのデータを直接参照 します。
また、Parquet ファイルを読み込む際は OPENROWSET により Data Lake 上のファイルを直接クエリ する必要があります。
CROSS APPLY や OPENJSON は JSON 向け機能のため不適切です。
したがって、外部テーブル+OPENROWSET の組み合わせが正しい選択となります。
外部テーブルの作成と使用
Q6.Apache Parquet 形式のバッチ データセットを Azure Data Factory で作成し、Azure Data Lake Storage Gen2 に保存しています。
これを Azure Synapse Analytics のサーバーレス SQL プールで使用します。
ストレージ コストを最小限に抑えるには、何を行うべきですか。
A. すべてのデータを文字列として Parquet ファイルに保存する
B. OPENROWSET を使用して Parquet ファイルをクエリする
C. Parquet ファイルの列のサブセットを含む外部テーブルを作成する
D. ファイルに Snappy 圧縮を使用する
回答
- C. Parquet ファイルの列のサブセットを含む外部テーブルを作成する
-
Parquet は列指向形式のため、必要な列だけを参照できる構成がコスト最適化に有効です。
外部テーブルで必要列のみに絞ることで、不要な列の読み取りや処理を減らし、サーバーレス SQL プールのスキャン量を抑制できます。
OPENROWSET は参照方法であり、保存コストそのものの最小化策ではありません。
試験では列指向形式の特性を活かした設計が重要です。
Synapse SQL で外部テーブルを使用する – Azure
Q7.Azure Synapse Analytics サーバーレス SQL プールを含む Azure サブスクリプションがあります。
プールで次のクエリを実行します。
SELECT * FROM OPENROWSET(BULK ‘https://mydatalake.blob.core.windows.net/data/**’, FORMAT = ‘CSV’) AS datarows; 次の記述について、正しい場合は「はい」、そうでない場合は「いいえ」を選択してください。
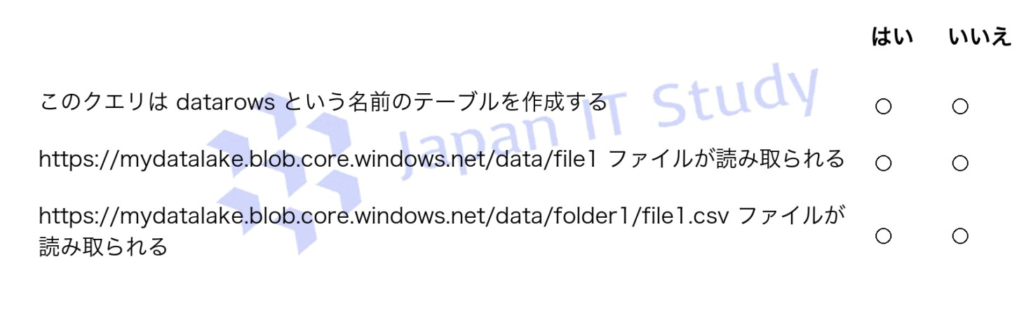
回答
- (下記画像参照)
-
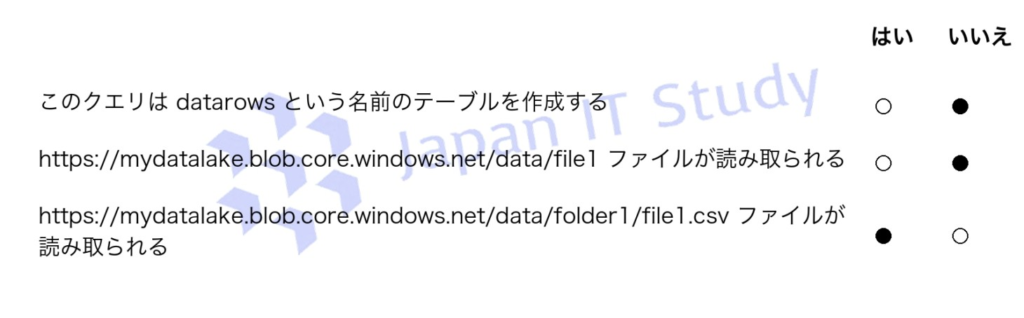
このクエリの datarows はテーブル名ではなく OPENROWSET の結果セットに付ける別名 なので、テーブルは作成されません。
また、BULK パスの末尾にある /** はフォルダーを再帰的に走査してサブフォルダー内のファイルを対象 とします。
そのため、data 直下の file1 は対象外で、data/folder1/file1.csv は読み取られます。
試験では ワイルドカード指定と別名の意味 を区別して理解することが重要です。
サーバーレス SQL プールを使用して、フォルダーと複数のファイルに対してクエリを実行する – Azure Synapse Analytics | Microsoft Learn
Q8.Azure Synapse Analytics 専用 SQL プールのファクト テーブルで、最適なクラスター化列ストア インデックスの圧縮とパフォーマンスを得るためのパーティション数はいくつですか。
A. 40
B. 240
C. 400
D. 2,400
回答
- A. 40
-
専用 SQL プールでは 内部的に60分散(Distribution)に分割されるため、列ストアの最適圧縮には各パーティションあたり約100万行が推奨されます。
総レコード数24億件より、24億 ÷(100万 × 60)=40 となります。
パーティションが多すぎると1パーティションあたりの行数が減少し、列ストア圧縮効率とクエリ性能が低下します。
したがって、適切な粒度で分割する設計が重要であり、最適なパーティション数は40です。
専用 SQL プールのベスト プラクティス – Azure Synapse Analytics
Q9.Azure Stream Analytics を使用してストリーミング データを処理しています。
各ナンバープレートごとに、10 分間隔で最後に通過した車両の時間を返すクエリを作成する必要があります。
適切な設定を選択してください。

回答
- (下記画像参照)
-
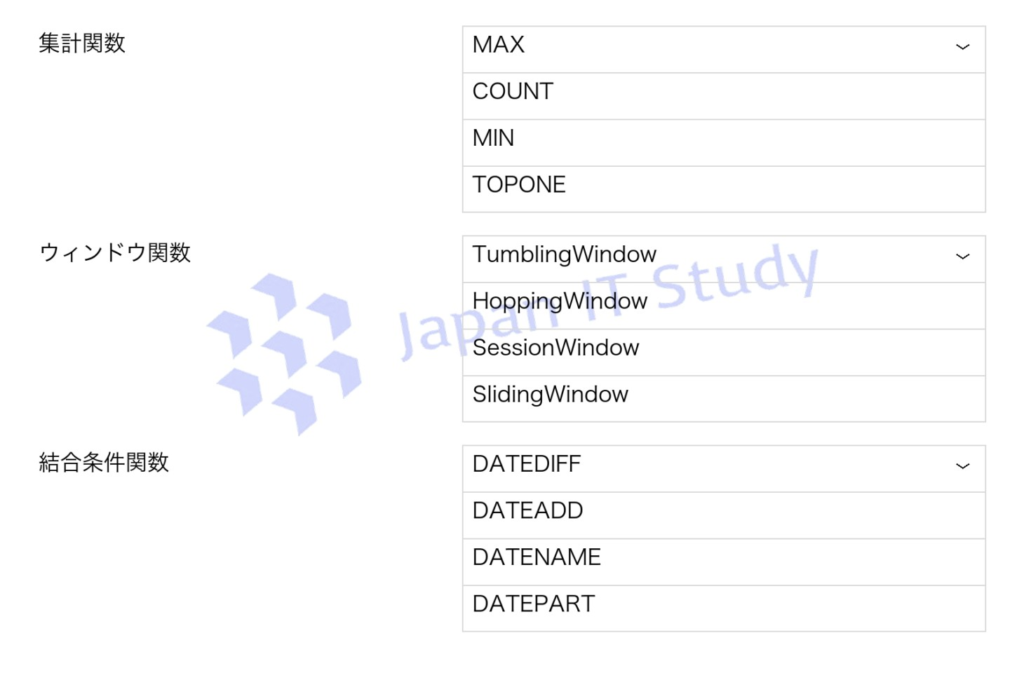
10分ごとの最後のイベントを取得するには、MAX(Time) を使用して各ウィンドウ内の最新時刻を取得します。
また、ウィンドウは重複しない固定間隔が必要なため TumblingWindow を使用して時間単位で区切るのが適切です。
さらに、元データと結合する際は時間差を評価するため DATEDIFF 関数で時間範囲を指定します。
これにより、各ウィンドウ内の最終イベントを正確に抽出できます。
Azure Stream Analytics のウィンドウ関数
Q10.Azure Data Lake Storage Gen2 Premium アカウントをデプロイし、365日より古いデータの削除と管理オーバーヘッド削減、およびコスト最小化を実現するには、適切な構成を選択してください。

回答
- (下記画像参照)
-
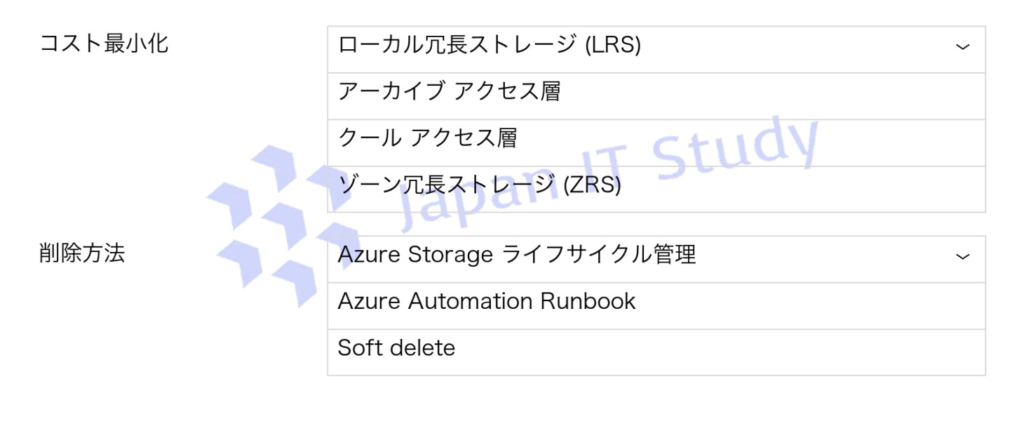
コスト最小化には冗長性を抑える必要があり、Locally-redundant storage(LRS)を選択することで最も低コストとなります。
また、365日経過後の自動削除には Azure Storage ライフサイクル管理を使用してポリシーで自動削除するのが最適です。
Automation Runbook は運用負荷が高く、Soft delete は削除防止機能のため要件に不適合です。
したがって、LRS+ライフサイクル管理の組み合わせが最適解です。
Azure Blob Storage のライフサイクル管理の概要
