

Q1.あなたは会社のWebサイト上で会社のビデオを検索するインターフェースを提供するために、Azure Video Indexer サービスを使用しています。
ユーザーが「ビデオに誰が登場しているか」に基づいてビデオを検索できるようにする必要があります。
あなたはどのようにするべきですか。
A. 人物モデルを作成し、そのモデルを動画に関連付ける
B. 人物オブジェクトを作成し、各オブジェクトに顔画像を提供する
C. 会社の全スタッフを Video Indexer に招待する
D. ビデオ内の顔を編集する
E. 言語モデルに名前をアップロードする
回答
- A. 人物モデルを作成し、そのモデルを動画に関連付ける
-
Azure AI Video Indexer(旧称: Azure Media Services Video Indexer)は、動画内の人物の顔を検出し識別する機能を提供します。
特定の人物を識別して検索可能にするには、アカウント内に人物モデルを作成し、そのモデルに顔を学習させる必要があります。
動画をアップロードまたは再インデックス化する際に人物モデルIDを指定すると、Video Indexerはそのカスタム人物モデルを使用して人物を識別します。
顔に名前を付けることで、その人物情報が人物モデルに追加され、以降の動画や過去の動画でも同一人物として認識されます。BはVideo Indexerの仕組みとは異なり、CやDは検索用の人物認識には関係ありません。Eの言語モデルも人物識別機能とは無関係です。
Video Indexer で人物モデルをカスタマイズする
Q2.vm1 という Azure 仮想マシン上で実行される app1 という Web アプリを作成します。
vm1 は vnet1 という Azure 仮想ネットワーク上にあります。
service1 という名前の新しい Azure Cognitive Search サービスを作成する予定です。
パブリック インターネット経由でトラフィックをルーティングせずに、app1 が service1 に直接接続できることを確認する必要があります。
解決策: service1 とパブリック エンドポイントをデプロイし、IP ファイアウォール ルールを構成します。
この方法は目標を満たしますか。
A. はい
B. いいえ
回答
- B. いいえ
-
IP ファイアウォール ルールは Azure Cognitive Search へのアクセス元 IP を制限する機能です。
しかし通信自体はパブリック エンドポイントを経由するため、トラフィックはインターネット経由になります。
そのため「パブリック インターネットを経由せずに接続する」という要件は満たしません。
この要件を満たすには Azure Private Link を使用してプライベート エンドポイントを作成し、仮想ネットワーク内のプライベート IP 経由でサービスへ接続する必要があります。
なお Azure Cognitive Search は現在 Azure AI Search という名称に変更されており、AI サービス群のブランド統一に伴う名称更新です。
Azure AI Search でプライベート エンドポイントを作成する
Q3.Azure OpenAI GPT 3.5 モデルを使用するチャットボットを構築します。
チャットボットからの応答の品質を向上させる必要があります。
ソリューションでは、開発労力を最小限に抑える必要があります。
目標を達成するための 2 つの方法は何ですか。
それぞれの正解は完全な解決策を示します。
A. モデルを微調整します
B. 根拠となるコンテンツを提供します
C. サンプルのリクエスト/レスポンスのペアを追加します
D. 独自のデータを使用して言語モデルを再トレーニングします
E. カスタム大規模言語モデル (LLM) をトレーニングします
回答
- B. 根拠となるコンテンツを提供します
C. サンプルのリクエスト/レスポンスのペアを追加します -
Azure OpenAI を使用したチャットボットの応答品質を短期間で向上させるには、モデルの再学習ではなくプロンプト設計を改善する方法が有効です。
根拠となるコンテンツを提供する方法は、外部データをモデルに参照させることで回答の正確性を高める手法であり、一般的に RAG(検索拡張生成)として実装されます。
これにより独自データを利用した回答が可能になり、誤った回答の発生を減らすことができます。
またサンプルのリクエストとレスポンスのペアをプロンプトに含める Few-shot プロンプティングは、望ましい回答形式や内容をモデルに示すことで品質を向上させます。
一方で微調整やモデル再学習、カスタム LLM の作成はデータ準備や学習プロセスが必要となるため開発工数が大きく、要件である開発労力の最小化に適していません。
プロンプト エンジニアリングの手法
Q4.Resource1 という名前の Azure Al Language リソースを含む Azure サブスクリプションがあります。
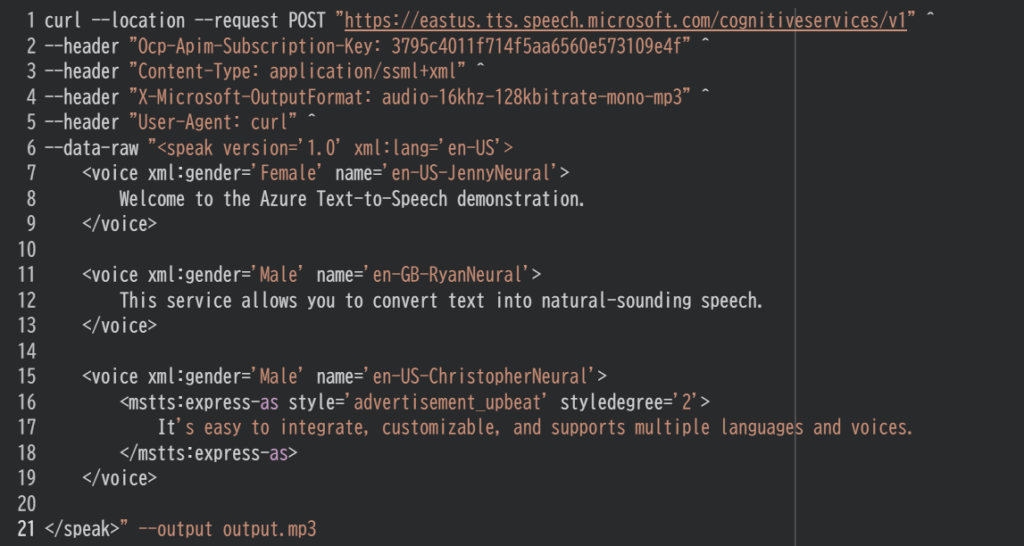
次の cURL コマンドを実行し、Output.mp3 ファイルを再生します。
次の各文について、正しい場合は「はい」、そうでない場合は「いいえ」を選択してください。

回答
- (下記画像参照)
-

この SSML には 3 つの voice 要素が含まれており、それぞれ異なる音声モデルが指定されています。
en-US-JennyNeural、en-GB-RyanNeural、en-US-ChristopherNeural は別々の音声モデルであるため、3 つの異なる声で文章が読み上げられます。
しかしアクセントは米国英語が 2 つ、英国英語が 1 つであるため、3 つすべてが異なるアクセントではありません。
また 3 つ目の音声では mstts:express-as style=”advertisement_upbeat” が指定されており、これは広告向けの明るい表現スタイルです。
そのためすべての文章がニュートラルなトーンで読み上げられるわけではありません。
Azure Speech の Text-to-Speech では SSML を使用することで音声、アクセント、話し方のスタイルなどを細かく制御できます。
音声合成マークアップ言語 (SSML) の概要
Q5.Azure AI Speech サービスを使用するアプリを構築しています。
アプリが Microsoft Entra ID トークンを使用してサービスに対して認証できることを確認する必要があります。
実行すべき 2 つのアクションはどれですか。
それぞれの回答がソリューションの一部となります。
A. 条件付きアクセスを作成する
B. プライベートエンドポイントを作成する
C. X.509 証明書を要求する
D. カスタムサブドメインを構成する
E. 仮想ネットワーク サービス エンドポイントを有効にする
回答
- B. プライベートエンドポイントを作成する
D. カスタムサブドメインを構成する -
Azure AI Speech サービスで Microsoft Entra ID トークン認証を使用する場合は、リソースにカスタムサブドメインを設定する必要があります。
カスタムサブドメインによりサービス固有のエンドポイント URL が作成され、Entra ID トークンによる認証が可能になります。
さらに Speech リソースにはプライベートエンドポイントを構成する必要があります。
プライベートエンドポイントを使用すると、仮想ネットワークから Azure AI Speech サービスへ安全に接続でき、Entra ID による認証がサポートされます。
条件付きアクセスはユーザーアクセス制御の機能であり、サービス認証設定ではありません。
また X.509 証明書や仮想ネットワーク サービス エンドポイントは Speech サービスの Entra ID トークン認証の要件ではありません。
Azure AI Speech サービスのロールベース アクセス制御
Q6.多言語チャットボットを構築しています。
ポジティブメッセージとネガティブメッセージに対して異なる回答を送信する必要があります。
どの2つのTextAnalyticsAPIを使用する必要がありますか?それぞれの正解は、解決策の一部を示しています。
A. 有名なナレッジベースからのリンクされたエンティティ
B. 感情分析
C. 主要なフレーズ
D. 言語を検出する
E. 固有表現抽出
回答
- B. 感情分析
D. 言語を検出する -
チャットボットがポジティブメッセージとネガティブメッセージに応じて異なる応答を返すには、ユーザーの文章の感情を判定する必要があります。
Azure AI Language の感情分析機能を使用すると、入力テキストをポジティブ、ネガティブ、ニュートラルなどに分類し、信頼度スコアとともに結果を取得できます。
これによりメッセージの感情に応じた応答処理を実装できます。
また多言語チャットボットではユーザー入力の言語が不明な場合があるため、言語検出 API を使用してテキストの言語を識別する必要があります。
言語を特定した後に感情分析を実行することで、複数言語に対応した感情判定が可能になります。
なお Text Analytics API は現在 Azure AI Language サービスの一部として提供されています。
感情分析とオピニオン マイニングとは
Q7.セマンティック カーネルを使用してアプリを構築しています。
アプリのプロンプトテンプレートには複雑なオブジェクトを含める必要があります。
ソリューションは、サブプロパティを含むオブジェクトをサポートする必要があります。
どの 2 つのプロンプト テンプレートを使用できますか。
それぞれの正解は完全なソリューションを示します。
A. 液体
B. JSONL
C. ハンドルバー
D. YAML
E. セマンティックカーネル
回答
- A. 液体
C. ハンドルバー -
Semantic Kernel では複雑なデータ構造をプロンプトに渡す場合、テンプレートエンジンを使用してオブジェクトのプロパティやコレクションを展開できます。
Liquid と Handlebars はどちらもテンプレート言語であり、ネストされたオブジェクトのサブプロパティへのアクセス、条件分岐、ループ処理などをサポートしています。
そのため複雑なオブジェクトをプロンプトに埋め込む用途に適しています。
一方 JSONL はデータセット形式でありテンプレート言語ではありません。
YAML は構成やデータ定義に使用されるフォーマットでありテンプレート処理機能はありません。
また Semantic Kernel はフレームワークでありテンプレート言語ではないため選択肢としては不適切です。
Semantic Kernel のプロンプト テンプレート構文
Q8.Microsoft Bot Framework を使用してボットを構築しています。
音声リクエストに応答するようにボットを設定する必要があります。
ソリューションは開発労力を最小限に抑える必要があります。
何をすべきでしょうか。
A. ボットを Azure にデプロイし、ボットを Direct Line Speech チャネルに登録します
B. Bot Framework SDK を使用してボットを Cortana と統合します
C. Speech サービスを呼び出してボットを関数に接続する Azure 関数を作成します
D. ボットを Azure にデプロイし、ボットを Microsoft Teams チャネルに登録します
回答
- B. Bot Framework SDK を使用してボットを Cortana と統合します
-
音声リクエストに対応するボットを最小の開発労力で実装するには、既存の音声対応チャネルを利用する方法が有効です。
Cortana は音声インターフェースを標準で提供しており、Bot Framework SDK を使用して統合することで音声入力と音声応答を自動的に処理できます。
そのため追加の音声処理ロジックを実装する必要がなく、開発作業を最小限に抑えることができます。
Direct Line Speech や Azure Functions を利用した方法では追加の構成やコード実装が必要になります。
また Microsoft Teams チャネルは主にテキストベースのボット対話を目的としているため、この要件には適していません。
Bot Framework SDK とは
Q9.Hub1 という名前の Microsoft Foundry ハブ、resource1 という名前の Azure OpenAI リソース、および User1 という名前のユーザーを含む Azure サブスクリプションがあります。
User1 が Hub1 で新しい Azure Content Understanding in Foundry Tools プロジェクトを作成できるようにする必要があります。
このソリューションは最小権限の原則に従う必要があります。
User1 に割り当てるべきロールはどれですか。
A. Azure AI 開発者
B. Cognitive Services OpenAI ユーザー
C. Cognitive Services OpenAI コントリビューター
D. Azure AI 管理者
回答
- B. Cognitive Services OpenAI ユーザー
-
Microsoft AI Foundry で Azure OpenAI を利用したプロジェクトを作成する場合、ユーザーは Azure OpenAI リソースを使用する権限を持つ必要があります。
Cognitive Services OpenAI ユーザー ロールは Azure OpenAI のモデルやエンドポイントを使用するための最小限の権限を提供します。
このロールを割り当てることで、ユーザーは Azure AI Foundry のツールから Azure OpenAI リソースを利用してプロジェクトを作成できます。
一方 Cognitive Services OpenAI コントリビューターや Azure AI 管理者はリソース管理権限を含むため、最小権限の原則を満たしません。
そのため必要最小限のアクセス権を提供する Cognitive Services OpenAI ユーザーが適切です。
Azure OpenAI Service のロールベース アクセス制御
Q10.Face APIの呼び出しを開発しています。この呼び出しでは、既存のemployeefacesというリストから類似の顔を検索する必要があります。employeefacesリストには60,000枚の画像が含まれています。
HTTPリクエストの本文はどのように記述すればよいでしょうか?
回答
- (下記画像参照)
-
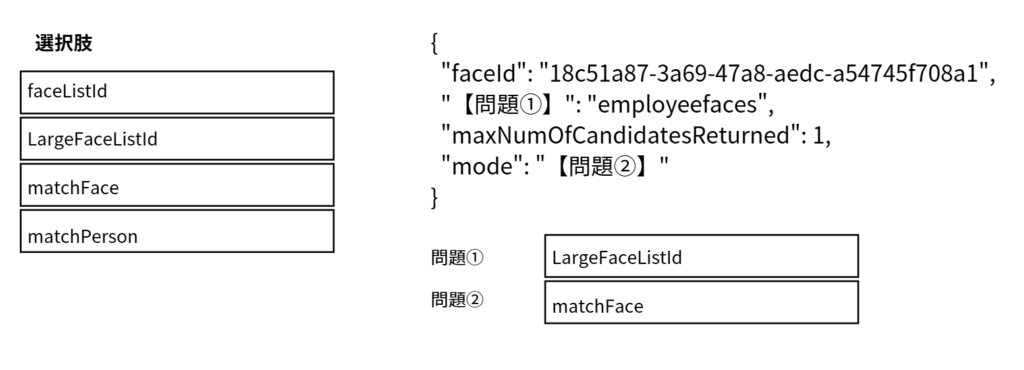
Face API で 60,000 件の顔画像を保持する場合は、通常の faceListId ではなく largeFaceListId を使用します。Face List は最大 1,000 顔までですが、Large Face List は最大 1,000,000 顔までサポートしているためです。
また、mode に指定する値は matchFace が適切です。matchFace は入力された顔と最も類似する顔を検索するモードであり、1 対 1 の類似検索に使用されます。
一方、matchPerson は同一人物候補を広く検索する用途です。
似た顔の検索
