

Q1.Microsoft Foundry プロジェクトに、ビジョン対応モデルのデプロイがあります。
テキストと画像URLを含むメッセージを送信するアプリケーションを開発する必要があります。
このソリューションでは、最も速い応答時間を確保する必要があります。
要求にはどのメッセージ構造を含める必要がありますか。
A. テキスト項目のみを含むユーザーメッセージを送信し、画像項目を別の要求で送信する。
B. コンテンツ配列内にテキスト項目と画像項目の両方を含むシステムメッセージ。
C. テキスト項目のみを含むシステムメッセージを送信し、画像項目を別の要求で送信する。
D. コンテンツ配列内にテキスト項目と画像項目の両方を含むユーザーメッセージ。
回答
- D. コンテンツ配列内にテキスト項目と画像項目の両方を含むユーザーメッセージ。
-
ビジョン対応モデルでは、テキストと画像を同じユーザーメッセージのcontent配列に含めて送信できます。
Microsoft Learnでも、画像URLを含む画像入力とテキスト入力を同一要求で扱う例が示されています。
したがって、別々の要求に分けず、ユーザーメッセージ内の同じコンテンツ配列に含めるDが最も応答時間を短くできます。
システムメッセージは主にモデルへの指示用であり、画像質問の入力本体には適しません。
ビジョン対応チャット モデルを使用する
Q2.Azure Speech SDK を使用して、リアルタイムの音声会話をサポートする Python アプリケーションを開発しています。
Azure Speech サービスへの接続を構成するには、どの Azure Speech クラスを使用する必要がありますか。
A. AudioConfig
B. AudioOutputConfig
C. SpeechSynthesizer
回答
- B. AudioOutputConfig
-
設問の正答表記はBですが、Microsoft Learn上では、Speechサービスへの接続情報は通常SpeechConfigで構成し、AudioOutputConfigは音声合成の出力先を構成するクラスです。
選択肢内で最も近いのは、音声合成の出力構成を扱うAudioOutputConfigです。
AudioConfigは入力または出力の音声構成、SpeechSynthesizerは合成処理を実行するクラスであり、接続そのものを構成する主役ではありません。
オーディオ出力設定クラス
Q3.Foundry Tools の Azure Content Understanding を使用して、ボイスメール録音を分析するアプリケーションを開発しています。
録音から文字起こしと構造化情報を抽出する必要があります。
どの種類のアナライザーを使用する必要がありますか。
A. 画像アナライザー
B. ビデオアナライザー
C. 音声アナライザー
D. ドキュメントアナライザー
回答
- C. 音声アナライザー
-
ボイスメール録音は音声データであるため、使用するのは音声アナライザーです。
Microsoft Learnでは、Content Understanding の音声アナライザーが会話音声の文字起こしや話者分離を行い、要約、感情、主要トピックなどの構造化フィールドを抽出できると説明されています。
画像、ビデオ、ドキュメント向けのアナライザーは、入力データの種類が異なるため、この要件には適しません。
Foundry Tools オーディオ ソリューションの Azure Content Understanding
Q4.会社でAIを使用するためのベストプラクティスを確認しています。各タスクは、Microsoftの責任あるAI原則のどの例ですか。
回答するには、適切な原則を正しいタスクにドラッグしてください。
各タスクは1回、複数回、またはまったく使用されない場合があります。
内容を表示するには、ペイン間の分割バーをドラッグするか、スクロールする必要がある場合があります。
回答
- 下記画像参照
-
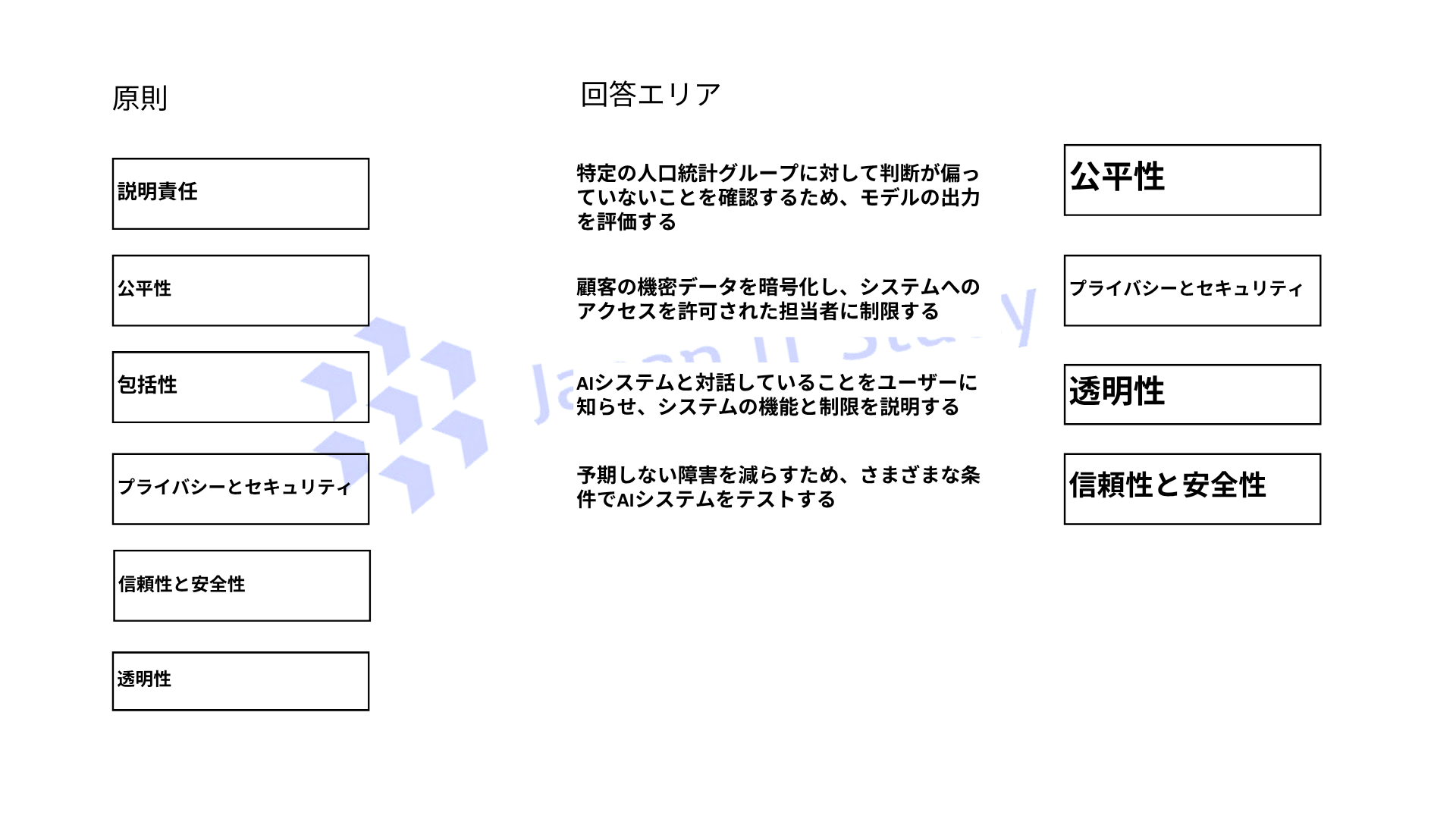
Microsoftの責任あるAI原則では、偏りを減らし公平な判断を目指すことはFairness、データ保護とアクセス制御はPrivacy and securityに該当します。
また、AI利用の明示や機能・制限の説明はTransparency、十分なテストにより安定動作と安全性を高めることはReliability and safetyです。
AI-901では、各原則を具体的な運用例に対応付けられることが重要です。
Microsoft の責任ある AI
Q5.Microsoft Foundry プロジェクトに、ビジョン対応モデルのデプロイがあります。
Azure OpenAI Responses APIを使用して、モデルにプロンプトを送信します。
分析のために画像を提供する必要があります。
要求にはどのコンテンツ項目を含める必要がありますか。
A. image_base64
B. image_generation
C. output_image
D. input_image
回答
- D. input_image
-
Azure OpenAI Responses APIでビジョン対応モデルに画像を渡す場合、画像は入力コンテンツとして扱うため、content配列にinput_imageを含めます。
image_urlを指定して画像を分析対象として渡す構造が想定されます。
image_generationは画像生成、output_imageは出力画像、image_base64はこの設問の正式なコンテンツ項目ではありません。
したがって、分析用画像を要求に含めるにはinput_imageが正解です。
Azure OpenAI Responses API を使用する
Q6.製品とその対象ユーザーに関する短い説明に基づいて、マーケティングメールの下書きを生成するAIソリューションを構築する必要があります。
どのAIワークロードを使用する必要がありますか。
A. 生成AI
B. コンピュータービジョン
C. テキスト分類
D. 音声認識
回答
- A. 生成AI
-
短い製品説明と対象ユーザーを入力として、マーケティングメールの下書きという新しい文章を作成する処理は、生成AIの代表的な用途です。
生成AIはプロンプトに基づいてテキスト、画像、コードなどの新しいコンテンツを生成します。
コンピュータービジョンは画像分析、テキスト分類は既存テキストの分類、音声認識は音声の文字起こしであり、新しいメール文面の生成には該当しません。
生成 AI とエージェントの概要
Q7.Microsoft Foundry プロジェクトに、生成AIモデルのデプロイがあります。
モデルによって生成される応答のコストを最小限に抑え、定義された長さ内に収める必要があります。
どのパラメーターを構成する必要がありますか。
A. Temperature
B. Max Completion Tokens
C. Top P
D. Model version settings
回答
- B. Max Completion Tokens
-
生成AIモデルの応答長を制御し、出力に使われるトークン数を抑えるには、Max Completion Tokensを構成します。
生成されるトークン数は利用量とコストに影響するため、上限を設定することで応答を定義された長さ内に収めやすくなります。TemperatureやTop Pは出力のランダム性を調整する設定であり、最大応答長を直接制限する設定ではありません。
Model version settingsも応答長の制御には使用しません。
Microsoft Foundry Models の Azure OpenAI REST API リファレンス
Q8.Microsoft Foundry プロジェクトに、生成AIモデルのデプロイがあります。
Foundry プレイグラウンドを使用してモデルをテストします。
デプロイ済みモデルに要求を送信するアプリケーションを開発する必要があります。
モデルを呼び出すために、アプリケーションにはどの情報を含める必要がありますか。
A. モデルトレーニングデータセット
B. Foundry プロジェクトの表示名
C. エクスポートされたプレイグラウンドセッション履歴
D. モデルエンドポイントと認証資格情報
回答
- D. モデルエンドポイントと認証資格情報
-
アプリケーションからデプロイ済みのAzure OpenAIモデルを呼び出すには、要求の送信先となるモデルエンドポイントと、APIキーまたはMicrosoft Entra IDなどの認証資格情報が必要です。
トレーニングデータセット、Foundryプロジェクトの表示名、プレイグラウンドのセッション履歴は、モデル呼び出しの認証や接続には使用しません。
なお、Azure AI Studioは現在Azure AI Foundryに統合・名称変更されています。
Azure OpenAI Responses API を使用する
Q9.Foundry Tools の Azure Content Understanding を使用して、ボイスメール録音を処理するアプリケーションを開発しています。
Azure Content Understanding は、音声をテキストに変換するためにどの機能を使用しますか。
A. Voice Live
B. キーフレーズ抽出
C. 文字起こし
D. 光学式文字認識(OCR)
回答
- C. 文字起こし
-
音声データをテキストへ変換する機能は、文字起こしです。Azure Content Understanding の音声分析では、会話や録音などの音声コンテンツを検索・分析可能なテキスト形式のトランスクリプトに変換できます。
Voice Liveはリアルタイム音声対話、キーフレーズ抽出は重要語句の抽出、OCRは画像や文書内の文字認識であり、ボイスメール音声のテキスト化には該当しません。
Foundry Tools オーディオ ソリューションの Azure Content Understanding
Q10.eコマース企業向けの Conversational Language Understanding(CLU)モデルを構築しています。
モデルが、意図されたスコープ外の発話を検出できるようにする必要があります。
何を行うべきですか。
A. モデルをエクスポートする
B. 新しいモデルを作成する
C. None インテントに発話を追加する
D. 事前構築済みの Task エンティティを作成する
回答
- C. None インテントに発話を追加する
-
Conversational Language Understanding(CLU)には、Noneインテントという特別なインテントが用意されており、どのカスタムインテントにも該当しない発話を分類するために使用されます。
スコープ外の質問や無関係な入力を正しく検出するには、Noneインテントに代表的な発話例を追加して学習させることが重要です。
これにより、モデルはユーザー入力が既存の意図に一致しない場合にNoneとして分類できるようになります。
None 意図
