

Q1.Fabric テナントにレイクハウスがあります。
Fabric ノートブックで、次のコードを使用して大きな DataFrame を保存しています。
df.write.partitionBy(“year”,”month”,”day”).mode(“overwrite”).parquet(“Files/SalesOrder”) 次の各ステートメントについて、そのステートメントが正しい場合は [はい] を選択します。
そうでない場合は [いいえ] を選択します。
注: 正しく選択するたびに 1 ポイントの価値があります。


回答
- (下記画像参照)
-

partitionBy(“year”,”month”,”day”) を指定すると、Spark は列値ごとに year、month、day の フォルダー階層を作成 してファイルを書き込みます。
パーティション単位でファイルを分けるため、分散環境では複数ノードで並列に読み取ることができます。
一方、コードでは圧縮オプションを指定していないため、圧縮利用はこの記述だけでは判断できません。
したがって 3 つ目は「いいえ」です。
Spark を使用したレイクハウスへのデータ ストリーミング – Microsoft Fabric
Q2.Fabric テナントに、Lakehouse1 という名前のレイクハウスがあります。
Lakehouse1 には、100 万個の Parquet ファイルを持つ Delta テーブルが含まれています。
過去 30 日間にテーブルから参照されていないファイルを削除する必要があります。
このソリューションでは、トランザクション ログの整合性を維持し、テーブルの ACID プロパティを保持する必要があります。
何をするべきですか。
A. optimize コマンドを実行し、v-order パラメーターを指定する。
B. OPTiMize コマンドを実行し、z-order パラメーターを指定する。
C. vacuum コマンドを実行する。
D. OneLake ファイル エクスプローラーからファイルを削除する。
回答
- C. vacuum コマンドを実行する。
-
Delta テーブルで参照されなくなった古いファイルを安全に削除するには、VACUUM コマンド を使用します。
VACUUM は Delta ログで参照されていないファイルを、保持期間の条件に従って削除するため、トランザクション ログの整合性 と ACID 特性を維持できます。
OPTIMIZE や V-Order は読み取り効率やファイル配置の最適化が目的であり、不要ファイル削除の主目的ではありません。
OneLake ファイル エクスプローラーで直接削除すると Delta ログと不整合 になる可能性があります。
Lakehouse で Delta テーブルのメンテナンスを実行する
Q3.Model 1 という名前のセマンティック モデルがあります。
Model 1 には、すべて Import モードを使用する 5 つのテーブルが含まれています。
Model1 には、HR という名前の動的な行レベル セキュリティ (RLS) ロールが含まれています。
HR ロールは、HR マネージャーが割り当てられている部門のデータのみを表示できるように、従業員データをフィルター処理します。
Model1 を Fabric テナントに発行し、RLS ロール メンバーシップを構成します。
モデルと関連レポートをユーザーと共有します。
HR マネージャーから、レポートに表示されるデータが不完全であると報告されました。
HR マネージャーに表示されるデータを検証するには、何をするべきですか。
A. HR マネージャーに、Microsoft Power BI Desktop でレポートを開くよう依頼する。
B. [ロールとしてテスト] を選択して、HR ロールとしてデータを表示する。
C. [ロールとしてテスト] を選択して、HR マネージャーとしてレポートを表示する。
D. HR 部門のフィルターの意図したロジックに一致するように、レポート内のデータをフィルター処理する。
回答
- C. [ロールとしてテスト] を選択して、HR マネージャーとしてレポートを表示する。
-
動的 RLS では、USERPRINCIPALNAME() などに基づき、ユーザーごとに表示される行が変わります。
そのため HR ロールだけで確認しても、特定の HR マネージャーに割り当てられた部門データを正しく検証できません。
Power BI サービスの ロールとしてテスト では、ロールや 特定のユーザー として表示を確認できます。
今回確認すべきなのは報告者本人に見える内容なので、HR マネージャーとしてレポートを表示する操作が 正答 です。
Power BI での行レベルのセキュリティ (RLS) – Microsoft Fabric | Microsoft Learn
Q4.Fabric テナントに、lakehouse1 という名前のレイクハウスがあります。
Lakehouse1 には Customer という名前の Delta テーブルが含まれています。
Customer に対してクエリを実行すると、クエリの実行が遅いことが分かりました。
テーブルでメンテナンスが実行されていないと考えています。
Customer に対してメンテナンス タスクが実行されたかどうかを識別する必要があります。
ソリューション: 次の Spark SQL ステートメントを実行します。
DESCRIBE HISTORY customer これは目標を満たしますか。
A. はい
B. いいえ
回答
- A. はい
-
DESCRIBE HISTORY は、Delta テーブルの操作レベルの履歴を返す読み取り専用コマンドです。
履歴には WRITE、MERGE、OPTIMIZE、VACUUM などの操作、実行時刻、ユーザー、操作メトリックが含まれます。
そのため Customer に対して メンテナンスが実行済みか確認 できます。
今回の目的は性能改善の実行ではなく、実施有無の識別です。
したがって DESCRIBE HISTORY customer は要件を満たします。
Inspect Delta table metadata – Microsoft Fabric | Microsoft Learn
Q5.Workspace1 という名前のワークスペースを含む Fabric テナントがあります。
Workspace1 には、LH1 という名前のレイクハウスと、DW1 という名前のウェアハウスが含まれています。
LH1 には、dbo スキーマにある signindata という名前のテーブルが含まれています。
signindata テーブル内のデータを重複排除するストアド プロシージャを DW1 に作成する必要があります。
T-SQL ステートメントをどのように完成させるべきですか。
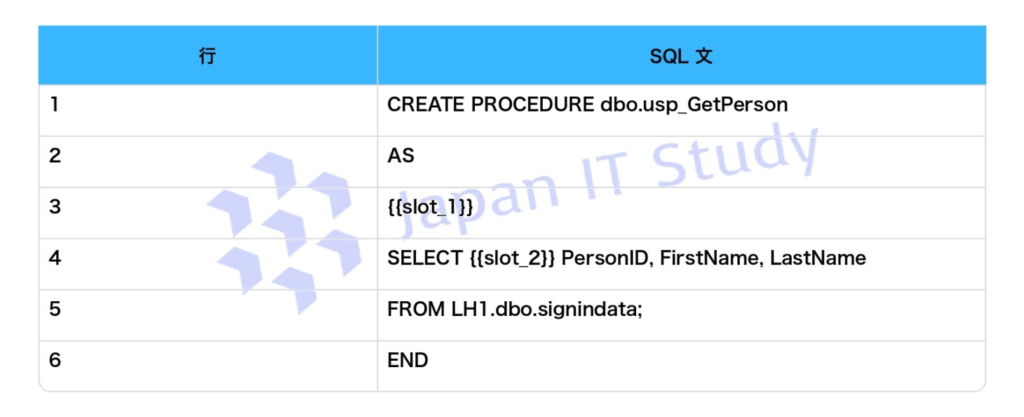

回答
- (下記画像参照)
-

Fabric Warehouse のストアド プロシージャは T-SQL で作成でき、AS の後に処理本体を記述します。
通常の処理ブロックを開始するには BEGIN を使用します。
分散トランザクションを開始する必要はなく、SET は処理ブロックの開始ではありません。
重複排除は PersonID、FirstName、LastName の一意な組み合わせを返せばよいため、SELECT の直後には DISTINCT を指定します。
GROUP BY でも似た結果は得られますが、集計しない重複排除では SELECT DISTINCT が最も適切です。
チュートリアル: ウェアハウス内のストアド プロシージャを使用してデータを変換する
Q6.OneLake に新しいセマンティック モデルを含む Fabric テナントがあります。
Fabric ノートブックを使用して、データを Spark DataFrame に読み込みます。
すべての文字列列と数値列について、最小値、最大値、平均、標準偏差の値を計算するためにデータを評価する必要があります。
ソリューション: 次の PySpark 式を使用します。
df.show() これは目標を満たしますか。
A. はい
B. いいえ
回答
- B. いいえ
-
df.show() は Spark DataFrame の内容を画面に表示するためのメソッドであり、列ごとの統計値を計算する処理ではありません。
求められているのは最小値、最大値、平均、標準偏差などの 記述統計の算出 です。
Fabric ノートブックでは display(df, summary = true) などにより DataFrame の統計概要を確認できます。
したがって、単に df.show() を実行しても、目標は満たされません。
Microsoft Fabric でのノートブックの視覚化
Q7.Workspace1 という名前のワークスペースを含む Fabric テナントがあります。
Workspace1 には、2 つの Microsoft Power BI レポートを持つ 1 つのセマンティック モデルが含まれています。
Microsoft 365 サブスクリプションには、DLP1 という名前のデータ損失防止 (DLP) ポリシーが含まれています。
Workspace1 内の項目に DLP1 を適用する必要があります。
何をするべきですか。
A. セマンティック モデルにマスター データの承認を適用する。
B. セマンティック モデルに認定済みの承認を適用する。
C. ワークスペース ID を作成する。
D. セマンティック モデルとレポートに秘密度ラベルを適用する。
回答
- D. セマンティック モデルとレポートに秘密度ラベルを適用する。
-
Microsoft Purview の DLP ポリシーを Fabric や Power BI の項目に適用するには、対象コンテンツを分類するための 秘密度ラベル が重要です。
秘密度ラベルはセマンティック モデルやレポートなどに適用でき、DLP ポリシーの条件として利用されます。
承認や認定は検出性や信頼性を高める機能であり、DLP の適用条件 にはなりません。
ワークスペース ID も外部リソース接続用であり、本要件とは無関係です。
したがって セマンティック モデルとレポートへ秘密度ラベルを適用 します。
Power BI の秘密度ラベル – Microsoft Purview Information Protection | Microsoft Learn
Q8.Workspace1 という名前の Fabric ワークスペースがあります。
Workspace1 には、Dataflow1 という名前のデータフローが含まれています。
Dataflow1 は 500 行のデータを返します。
クエリ結果内の各列について、最小値と最大値を識別する必要があります。
どの 3 つのデータ ビュー オプションを選択するべきですか。
各正解はソリューションの一部です。
A. 列の品質の詳細を表示する。
B. 詳細ウィンドウに列プロファイルを表示する。
C. 詳細ウィンドウを有効にする。
D. 列値の分布を表示する。
E. 列プロファイルを有効にする。
回答
- B. 詳細ウィンドウに列プロファイルを表示する。
C. 詳細ウィンドウを有効にする。
E. 列プロファイルを有効にする。 -
Power Query のデータ プロファイリングでは、列の品質、列の分布、列プロファイルを確認できます。
最小値や最大値などの統計情報を列単位で確認するには、まず 列プロファイルを有効化 し、結果を表示するために 詳細ウィンドウを有効化 します。
さらに詳細ウィンドウに列プロファイルを表示することで、各列の統計情報を確認できます。
列の品質は有効・空・エラーの割合、列の分布は値の分布確認が中心であり、最小値と最大値の確認には不十分です。
データ プロファイリング ツールの使用 – Power Query
Q9.Workspace1 と Workspace2 という名前の 2 つのワークスペース、および User1 という名前のユーザーを含む Fabric テナントがあります。
User1 が次のタスクを実行できるようにする必要があります。
新しいドメインを作成する。
subdomain1 と subdomain2 という名前の 2 つのサブドメインを作成する。
Workspace1 を subdomain1 に割り当てる。
Workspace2 を subdomain2 に割り当てる。
このソリューションは最小特権の原則に従う必要があります。
User1 にどのロールを割り当てるべきですか。
A. ドメイン管理者
B. ドメイン共同作成者
C. ワークスペース管理者
D. Fabric 管理者
回答
- D. Fabric 管理者
-
Fabric ドメインでは、新しいドメインの作成 は Fabric 管理者のみが実行できます。
ドメイン管理者は、自分が管理者である既存ドメインのサブドメイン作成やワークスペース割り当ては可能ですが、新規ドメインの作成権限までは持ちません。
ドメイン共同作成者は主に自分が管理者であるワークスペースを既存ドメインへ割り当てる役割であり、ワークスペース管理者もドメイン管理権限ではありません。
したがって、要件全体を満たす最小の選択肢は Fabric 管理者 です。
ドメイン – Microsoft Fabric | Microsoft Learn
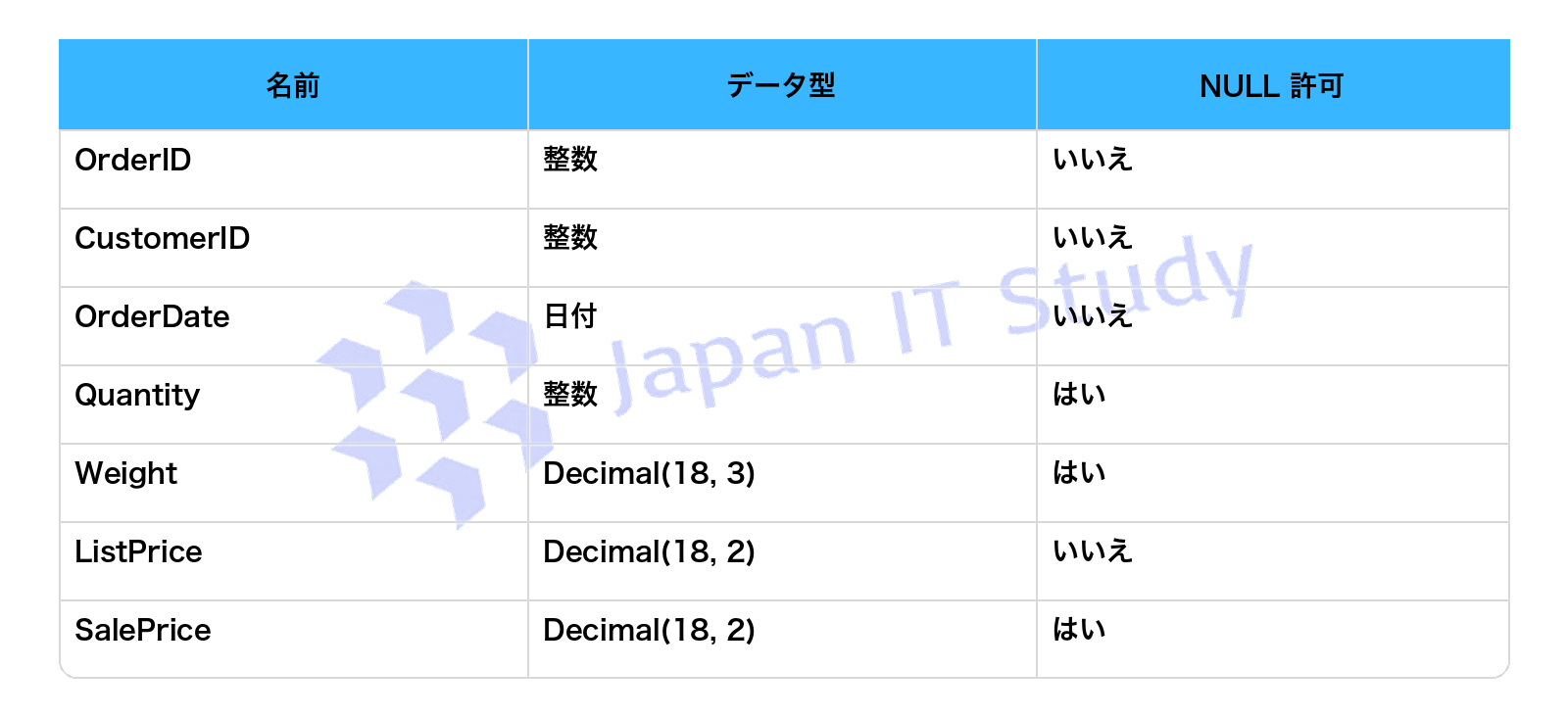
Q10.Sales.Orders という名前のテーブルを含む Fabric ウェアハウスがあります。
Sales.Orders には次の列が含まれています。
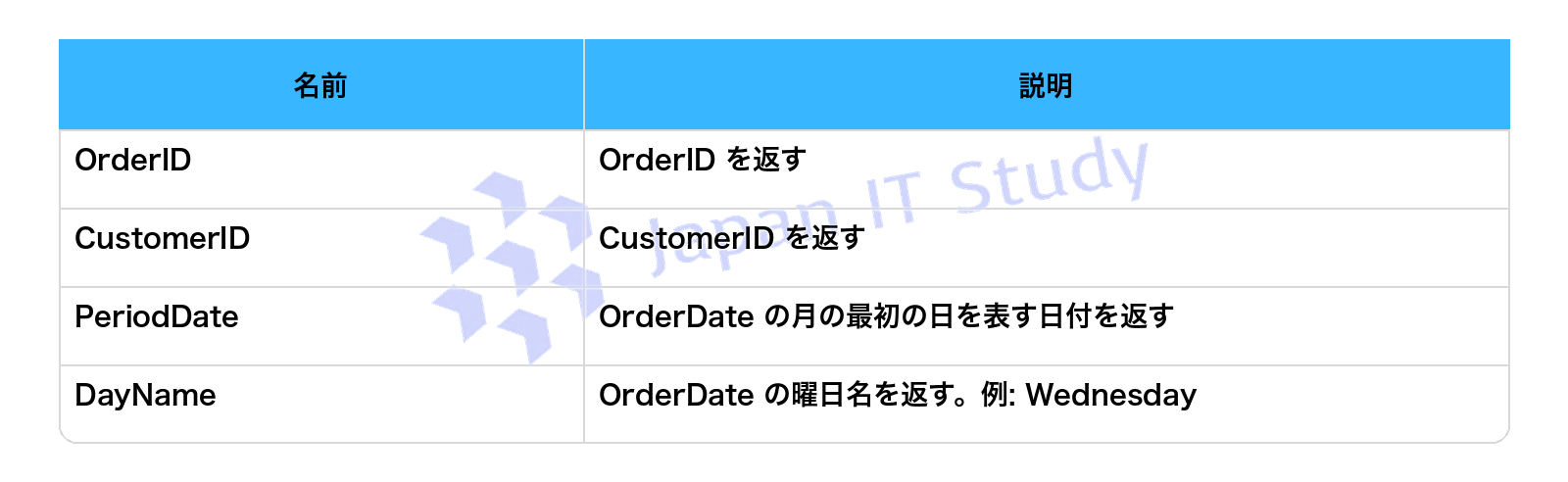
次の列を返す T-SQL クエリを記述する必要があります。
コードをどのように完成させるべきですか。
回答するには、回答領域で適切なオプションを選択してください。
注: 正しく選択するたびに 1 ポイントの価値があります。
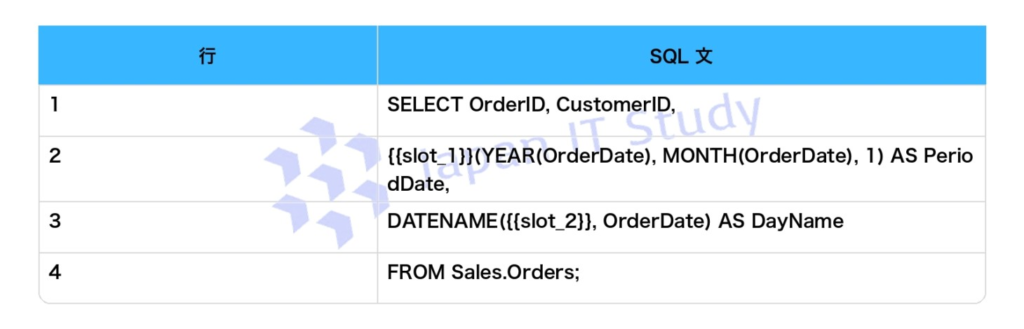
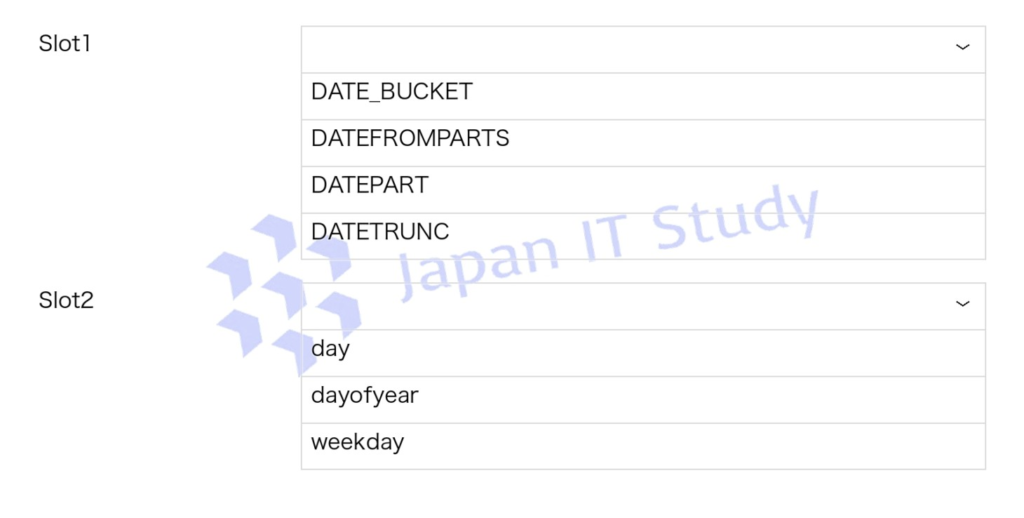
回答
- (下記画像参照)
-
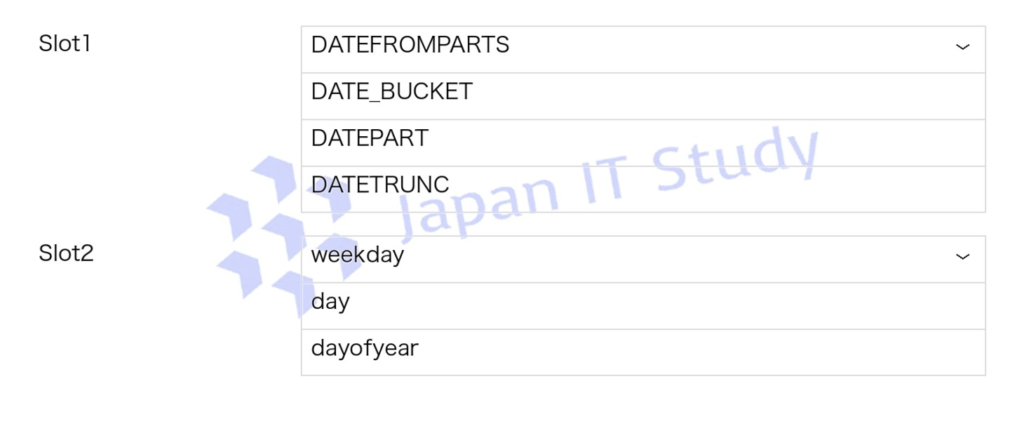
PeriodDate は OrderDate の年月を使い、日を 1 に固定した日付を返す必要があるため、DATEFROMPARTS が適切です。
DATEPART は数値の一部を返す関数で、DATETRUNC や DATE_BUCKET はこの設問のコード形式とは一致しません。
DayName は曜日名を返す必要があるため、DATENAME の datepart には weekday を指定します。
day や dayofyear は日や通算日を返す指定であり、曜日名にはなりません。
したがって、DATEFROMPARTS と weekday を選択します。
日付と時刻のデータ型および関数 (Transact-SQL)
